Sign Langauge Part 1: Modules
This blog is about intro to end to end sign langauge video generation. A lot of effort and work has been done by the community to detect signs from a signer video, but when it comes to generation of video from sign language text there are very limited works that achieved realistic results.
Introduction
Challenges we face while generating the sign video:
-
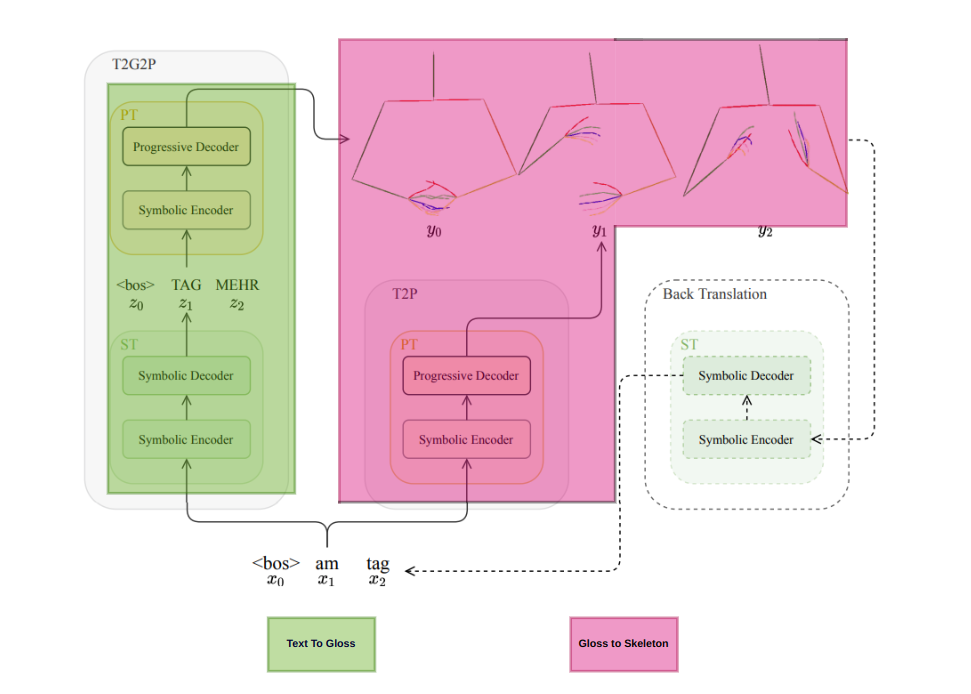
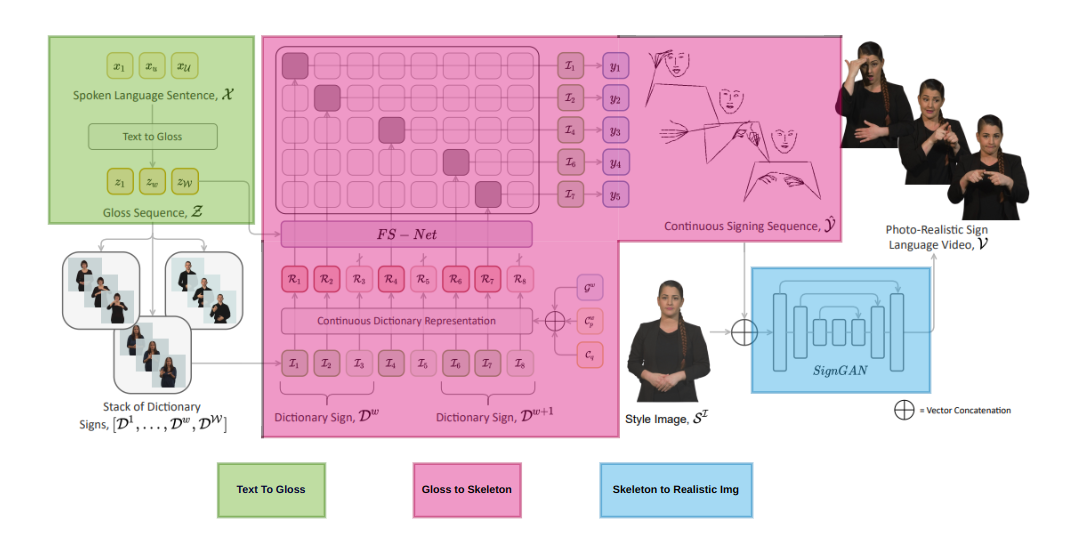
The human text to gloss. The gloss is the sequnce of words signed by the person. The words get juggled when the signer is signing. So we need to find a way to convert the text to gloss. NLP(transformers) is a good way to convert a text to gloss, since the transformer architectures are good at text to text translation.
-
The gloss to be mapped with frames of a person, is another task, one way is to generate skeleton points of a person and then map the gloss to the skeleton points. This is a very challenging task, since the gloss is not a one to one mapping with the skeleton points. The gloss is a sequence of words, and the skeleton points are a sequence of points. So we need to find a way to map the gloss to the skeleton points. RNN, LSTM, Transformers can even help us to achieve this task.
-
Use the generated skeleton and convert this to a video which is human realistic. Probably using PIX2PIX GANs can help us to achieve this task. The GANs are good at image to image translation. So we can use the generated skeleton points and convert it to a video.
When someone says about sign langauge its just not about move hands and fingers alone, we need to even observe the facial expression of the signer to understand the meaning of the sign.
Data
I am using German Sign Langauge Dataset and Indian Sign langauge Datasets, since they are good number of samples. Basically there are 2 kinds of datasets,
- Sign langauge videos for the particular word.
- Sign langauge videos for the entire sentence.
Indian Sign Langauge Datasets:
German Sign Langauge Datasets:
- meinedgs - meinedgs Dataset (Sentences, words, paragraphs).
- RWTH - RWTH-PHOENIX-Weather 2014 Dataset (Sentences).
I personally think meinedgs dataset is best of all, it is recording between 2 german signers, we have the english text, german text, german gloss, good quality of signers in the video, the videos timestamps(start, end) are also given for each specific gloss. So we can use this dataset to train our model. When it comes to Indian sign langauge, INCLUDE dataset seems to be better since there good amount of samples.